上一章 【认识 MIME 和 HTTP】。
我们认识和了解了 MIME 的概念和作用,也简单地学习了通过浏览器控制台查看请求和返回的用法。
通过对不同的 HTML、CSS、JS 文件进行判断,设置不同的 MIME 值,得以让我们的浏览器正正确地接收和显示不同的文件内容,渲染出正确的效果。
但真实场景中,远远不止这三种类型的文件,用成百上千来形容也不为过。
{
"application/atom+xml": {
"extensions": ["atom"]
},
"application/java-archive": {
"extensions": ["jar", "war", "ear"]
},
"application/javascript": {
"extensions": ["js"]
},
"application/json": {
"extensions": ["json"]
},
"application/msword": {
"extensions": ["doc"]
},
"application/pdf": {
"extensions": ["pdf"]
},
"application/postscript": {
"extensions": ["ps", "eps", "ai"]
},
"application/rss+xml": {
"extensions": ["rss"]
},
"application/rtf": {
"extensions": ["rtf"]
},
"application/vnd.apple.mpegurl": {
"extensions": ["m3u8"]
}
}上图是一个开源的项目,地址是:https://github.com/jshttp/mime-db。
该项目对所有文件类型的扩展名和 MIME 类型进行了映射。
知道文件扩展名,就能找到对应的 MIME 类型。
知道 MIME 类型,就能知道哪些文件扩展名可以匹配。
但是,也正如它的仓库名字 mime-db 所表达的,它是一个映射库。
也就是说,它只是提供了一堆数据,具体如何实现根据扩展名获取 MIME 类型,那得用到另外一个开源项目 https://github.com/jshttp/mime-types。
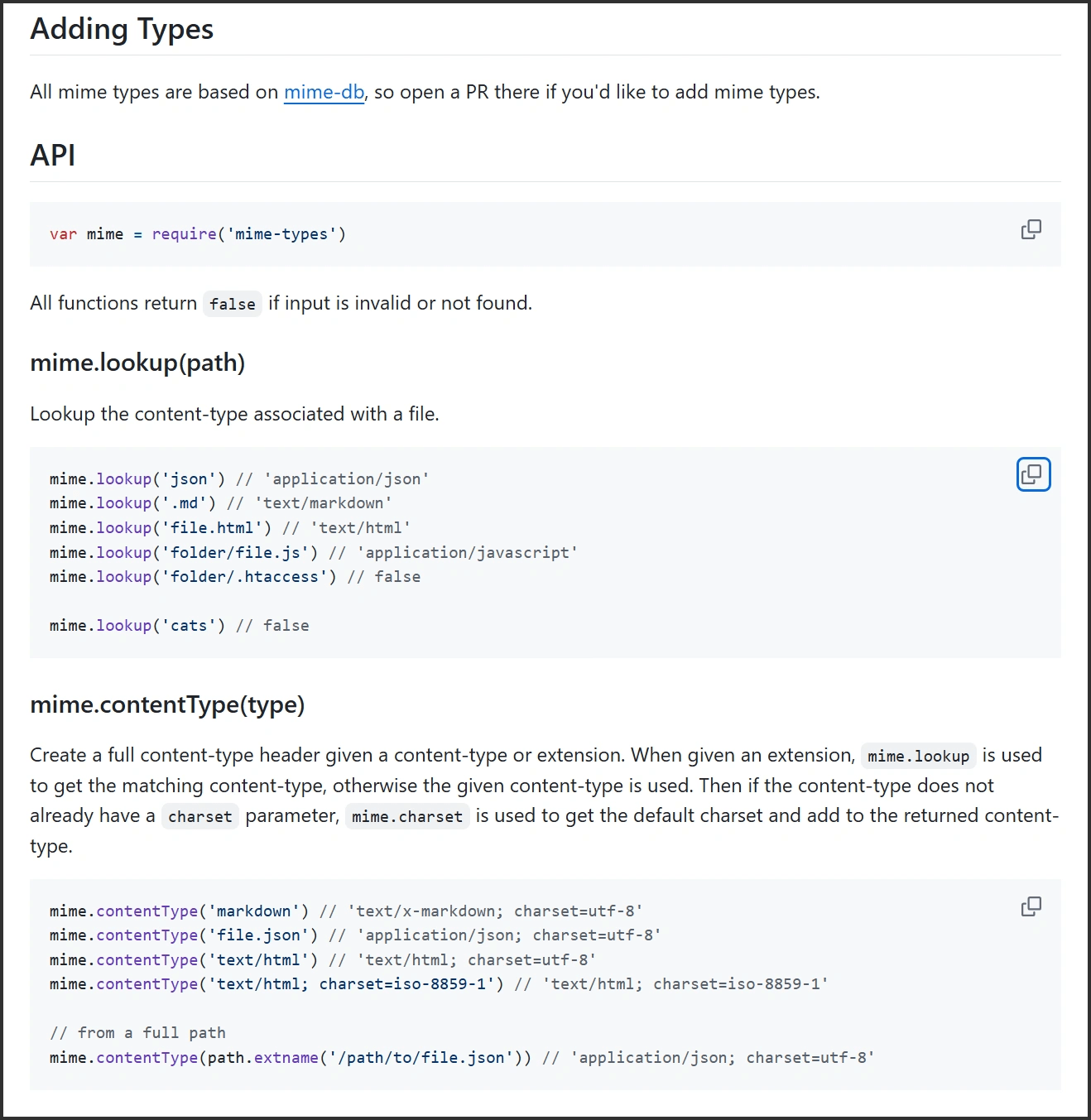
从截图中就能看到相关的文字说明,这个项目依赖了 mime-db 项目。而且,这 2 个项目是同一批作者。
mime-types 提供了多个方法,比较常用的就是 lookup 方法,根据文件扩展名,返回对应的 MIME 值。
目前,这 2 个项目在 npm平台 的周下载量,均在 5千万次以上,众多知名项目都依赖于这 2 个项目。在 github 上,有 3千多万个 仓库依赖了 mime-types。
而现在,我们的 web 服务器也将使用 mime-types 完成我们今天的主题:静态资源服务器。
实现静态资源服务器
{
"name": "CoolApi",
"version": "1.0.0",
"description": "我的接口框架",
"type": "module",
"main": "server.js",
"scripts": {
"dev": "nodemon server.js"
},
"dependencies": {
"mime-types": "^2.1.35"
}
}在用 mime-types 之前呢,首先要安装这个依赖。
下一步呢,就在我们的项目中用起来。
import { createServer } from 'node:http';
import { readFileSync } from 'node:fs';
import { lookup } from 'mime-types';
const server = createServer((req, res) => {
if (req.url === '/') {
req.url = '/index.html';
}
res.setHeader('Content-Type', lookup(req.url));
res.end(readFileSync(`./public/${req.url}`));
});
server.listen(3000, '127.0.0.1', () => {
console.log('服务已启动,监听端口为:3000');
});此时项目的整体结构如下:
CoolApi
├── public
│ ├── index.html
│ ├── index.css
│ └── favicon.ico
├── package.json
└── server.js可以看到,我们把静态资源都放到多了public目录下,同时,也提供了一个标题栏收藏图标favicon.ico。

这个文件我放到这里,右键另存为即可。
这段代码涉及到几个步骤,一一说明下。
首先,当我们直接在浏览器端输入 http://127.0.0.1:3000 访问的时候,请求的 url 值是 /。
没有任何扩展名,也没有文件名,服务器遇到这种情况怎么办呢?总不能什么也不返回吧,那么我们的 WEB 服务器探索之路就到此终止了。
市面上的 WEB 服务器,比如 Apache、Nginx、Caddy、Tomcat。或者 Node.js 中的 Koa、Express、Fastify 等等。一般都会对这种静态文件服务器的 “根” 请求,返回默认的 index.html 文件。
我们这里也不例外,如果是 根 (/) 请求,就把请求地址改成 index.html。
然后,根据我们请求的资源,通过 mime-types 的 lookup 函数,去获取该文件扩展名所对应的 MIME 值,设置给返回数据的请求头中的 Content-Type 属性。
如果对这个设置头部属性印象模糊了,请看前面章节内容。
最后,再通过 readFileSync 函数,读取对应的请求文件内容,返回给浏览器。
那么经过这么一操作,我们的代码量不仅减少了,程序也更健壮了,支持的文件类型也更多了,可以不加多余的代码逻辑,就能显示不同的资源了。
当然,目前的功能,距离真正的流行的 Web 框架还差得远,同时正如前文所说,本小册分为两大部分。
第一大部分,是通过一个 Web 服务器的诞生,来进一步理解其工作流程。
第二大部分,就是通过我们这个 Web 服务器,来写一个全栈的个人博客项目。
这样,我们就能够掌握 Node.js 全栈开发的秘诀,不管是后面使用其他 Web 框架,还是自己写一个前后端一体化的全栈产品,都会更加轻松。